Dagstuhl Seminar 19052
Computational Methods for Melody and Voice Processing in Music Recordings
( Jan 27 – Feb 01, 2019 )




(Click in the middle of the image to enlarge)
Permalink
Please use the following short url to reference this page:
https://www.dagstuhl.de/19052
Organizers
- Emilia Gómez (UPF - Barcelona, ES)
- Meinard Müller (Universität Erlangen-Nürnberg, DE)
- Yi-Hsuan Yang (Academica Sinica - Taipei, TW)
Contact
- Michael Gerke (for scientific matters)
- Susanne Bach-Bernhard (for administrative matters)
Dagstuhl Seminar Wiki
- Dagstuhl Seminar Wiki (Use personal credentials as created in DOOR to log in)
Shared Documents
- Dagstuhl Materials Page (Use personal credentials as created in DOOR to log in)
Press/News
Impacts
- Dagstuhl ChoirSet : a Multitrack Dataset for MIR Research : article - Rosenzweig, Sebastian; Cuesta, Helena; Weiß, Christof; Scherbaum, Frank; Gomez, Emilia; Müller, Meinard - International Society for Music Information Retrieval, 2020. - pp. 98-110 - (Transactions of the International Society for Music Information Retrieval ; 3. 2020, 1 : article).
- Dagstuhl ChoirSet : dataset - Rosenzweig, Sebastian; Cuesta, Helena; Weiß, Christof; Scherbaum, Frank; Gomez, Emilia; Müller, Meinard - Zenodo, 2020.
In our daily lives, we are constantly surrounded by music, and we are deeply influenced by music. Making music together can create strong ties between people, while fostering communication and creativity. This is demonstrated, for example, by the large community of singers active in choirs or by the fact that music constitutes an important part of our cultural heritage. The availability of music in digital formats and its distribution over the world wide web has changed the way we consume, create, enjoy, explore, and interact with music. To cope with the increasing amount of digital music, one requires computational methods and tools that allow users to find, organize, analyze, and interact with music – topics that are central to the research field known as Music Information Retrieval (MIR).
This Dagstuhl Seminar is devoted to a branch of MIR that is of particular importance: processing melodic voices using computational methods. It is often the melody, a specific succession of musical tones, which constitutes the leading element in a piece of music. In this seminar we want to discuss how to detect, extract, and analyze melodic voices as they occur in recorded performances of a piece of music. Even though it may be easy for a human to recognize and hum a main melody, the automated extraction and reconstruction of such information from audio signals is extremely challenging due to superposition of different sound sources as well as the intricacy of musical instruments and, in particular, the human voice. As one main objective of the seminar, we want to critically review the state of the art of computational approaches to various MIR tasks related to melody processing including pitch estimation, source separation, instrument recognition, singing voice analysis and synthesis, and performance analysis (timbre, intonation, expression). Second, we aim at triggering interdisciplinary discussions that leverage insights from fields such as audio processing, machine learning, music perception, music theory, and information retrieval. Third, we shall explore novel applications in music and multimedia retrieval, content creation, musicology, education, and human-computer interaction.
By gathering internationally renowned key players from different research areas, our goal is to highlight and better understand the problems that arise while dealing with a highly interdisciplinary topic such as melody extraction or voice separation. Special focus will be put on increasing the diversity of the MIR community in collaboration with the mentoring program developed by the Women in Music Information Retrieval (WiMIR) initiative. General questions and issues that may be addressed in this seminar include, but are not limited to the following list:
- Model-based melody extraction and singing voice separation
- Multipitch and predominant frequency estimation
- Modeling of musical aspects such as vibrato, tremolo, and glissando
- Informed singing voice separation (exploiting additional information such as score and lyrics)
- Integrated models for voice separation, melody extraction, and singing analysis
- Alignment methods for synchronizing lyrics and recorded songs
- Assessment of singing style, expression, skills, and enthusiasm
- Content-based retrieval (e.g. query-by-humming, theme identification)
- Data mining techniques for identifying singing-related resources on the world wide web
- Collecting and annotating musical sounds via crowdsourcing
- User interfaces for singing information analysis and visualization
- Singing for gaming and medical purposes
- Understanding expressiveness in singing
- Extraction of emotion-related parameters from melodic voices
- Extraction of vocal quality descriptors
- Singing voice synthesis and transformation
- Cognitive and sensorimotor factors in singing
- Deep learning approaches for melody extraction and voice processing
- Deep autoencoder models for feature design and classification
- Hierarchical models for short-term/long-term dependencies
 Creative Commons BY 3.0 DE
Creative Commons BY 3.0 DE
 Emilia Gómez, Meinard Müller, and Yi-Hsuan Yang
Emilia Gómez, Meinard Müller, and Yi-Hsuan Yang
- Chor aus Wissenschaftlern will Beitrag zur KI-Forschung leisten
Article in Forschung & Lehre (in German) from August 28, 2020 - Dagstuhler Gesänge für die Wissenschaft
Press release (in German) - Den Gesang aus der Musik heraushören
Article in OPUS Kulturmagazin (in German) - Den Gesang aus der Musik heraushören
Press release (in German)
In this executive summary, we give an overview of computational melody and voice processing and summarize the main topics covered in this seminar. We then describe the background of the seminar's participants, the various activities, and the overall organization. Finally, we reflect on the most important aspects of this seminar and conclude with future implications and acknowledgments.
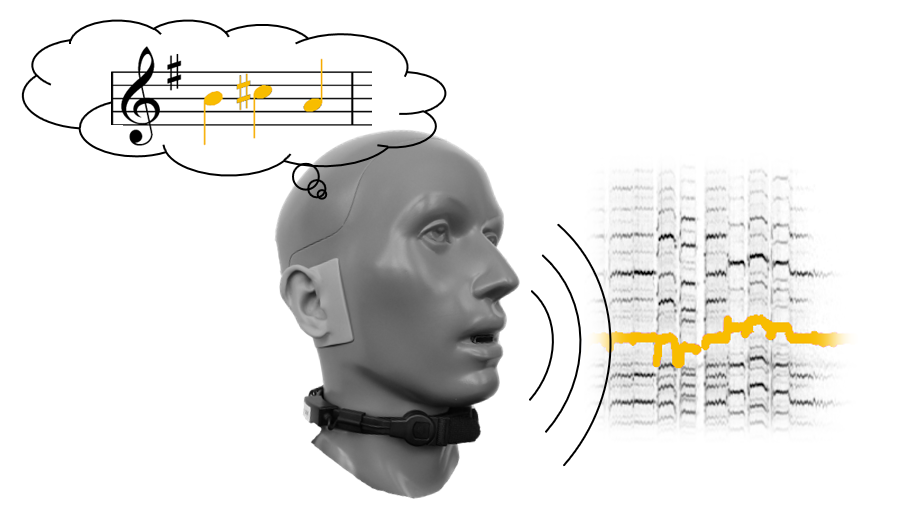
Overview
When asked to describe a specific piece of music, we are often able to sing or hum the main melody. In general terms, a melody may be defined as a linear succession of musical tones expressing a particular musical idea. Because of the special arrangement of tones, a melody is perceived as a coherent entity, which gets stuck in a listener’s head as the most memorable element of a song. As the original Greek term meloidía (meaning “singing” or “chanting”) implies, a melody is often performed by a human voice. Of course, a melody may also be played by other instruments such as a violin in a concerto or a saxophone in a jazz piece. Often, the melody constitutes the leading element in a composition, appearing in the foreground, while the accompaniment is in the background. Sometimes melody and accompaniment may even be played on a single instrument such as a guitar or a piano. Depending on the context and research discipline (e. g., music theory, cognition or engineering), one can find different descriptions of what may be meant by a melody. Most people would agree that the melody typically stands out in one way or another. For example, the melody often comprises the higher notes in a musical composition, while the accompaniment consists of the lower notes. Or the melody is played by some instrument with a characteristic timbre. In some performances, the notes of a melody may feature easily discernible time–frequency patterns such as vibrato, tremolo, or glissando. In particular, when considering performed music given in the form of audio signals, the detection, extraction, separation, and analysis of melodic voices becomes a challenging research area with many yet unsolved problems. In the following, we discuss some MIR tasks related to melody processing, indicating their relevance for fundamental research, commercial applications, and society.
The problem of detecting and separating melodic voices in music recordings is closely related to a research area commonly referred to as source separation. In general, audio signals are complex mixtures of different sound sources. The sound sources can be several people talking simultaneously in a room, different instruments playing together, or a speaker talking in the foreground with music being played in the background. The general goal of source separation is to decompose a complex sound mixture into its constituent components. Source separation methods often rely on specific assumptions such as the availability of multiple channels, where several microphones have been used to record the acoustic scene from different directions. Furthermore, the source signals to be identified are assumed to be independent in a statistical sense. In music, however, such assumptions are not applicable in many cases. For example, musical sound sources may outnumber the available information channels, such as a string quartet recorded in two-channel stereo. Also, sound sources in music are typically highly correlated in time and frequency. Instruments follow the same rhythmic patterns and play notes which are harmonically related. This makes the separation of musical voices from a polyphonic sound mixture an extremely difficult and generally intractable problem.
When decomposing a music signal, one strategy is to exploit music-specific properties and additional musical knowledge. In music, a source might correspond to a melody, a bass line, a drum track, or a general instrumental voice. The separation of the melodic voice, for example, may be simplified by exploiting the fact that the melody is often the leading voice, characterized by its dominant dynamics and by its temporal continuity. The track of a bass guitar may be extracted by explicitly looking at the lower part of the frequency spectrum. A human singing voice can often be distinguished from other musical sources due to characteristic time--frequency patterns such as vibrato. Besides such acoustic cues, score-informed source separation strategies make use of the availability of score representations to support the separation process. The score provides valuable information in two respects. On the one hand, pitch and timing of note events provide rough guidance within the separation process. On the other hand, the score offers a natural way to specify the target sources to be separated.
In this seminar, we discussed source separation techniques that are particularly suited for melodic voices. To get a better understanding of the problem, we approached source separation from different directions including model-based approaches that explicitly exploit acoustic and musical assumptions as well as data-driven machine learning approaches.
Given a music recording, melody extraction is often understood in the MIR field as the task of extracting a trajectory of frequency values that correspond to the pitch sequence of the dominant melodic voice. As said before, melody extraction and source separation are highly related: while melody extraction is much easier if the melodic source can be isolated first, the source separation process can be guided if the melodic pitch sequence is given a priori. However, both tasks have different goals and involve different challenges. The desired output of melody extraction is a trajectory of frequency values, which is often sufficient information for retrieval applications (e.,g., query-by-humming or the search of a musical theme) and performance analysis. In contrast, for music editing and audio enhancement applications, source separation techniques are usually needed.
In the seminar, we addressed different problems that are related to melody extraction. For example, the melody is often performed by a solo instrument, which leads to a problem also known as solo-accompaniment separation. The estimation of the fundamental frequency of a quasi-periodic signal, termed mono-pitch estimation, is a long-studied problem with applications in speech processing. While mono-pitch estimation is now achievable with reasonably high accuracy, the problem of multi-pitch estimation with the objective of estimating the fundamental frequencies of concurrent periodic sounds remains very challenging. This particularly holds for music signals, where concurrent notes stand in close harmonic relation. For extreme cases such as complex orchestral music where one has a high level of polyphony, multi-pitch estimation becomes intractable with today's methods.
Melodic voices are often performed by singers, and the singing voice is of particular importance in music. Humans use singing to create an identity, express their emotions, tell stories, exercise creativity, and connect while singing together. Because of its social, cultural, and educational impact, singing plays a central role in many parts of our lives, it has a positive effect on our health, and it creates a link between people, disciplines, and domains (e.g., music and language). Many people are active in choirs, and vocal music makes up an important part of our cultural heritage. In particular in Asian countries, karaoke has become a major cultural force performed by people of all age groups. Singing robots, vocaloids, or synthesizers such as Hatsune Miku (https://en.wikipedia.org/wiki/Hatsune_Miku) have made their way into the mass market in Japan. Thanks to digitization and technologies, the world wide web has become an important tool for amateur and professional singers to discover and study music, share their performances, get feedback, and engage with their audiences. An ever-increasing amount of music-related information is available to singers and singing enthusiasts, such as music scores (For example, the Choral Public Domain Library currently hosts free scores of at least 24963 choral and vocal works by at least 2820 composers, see http://www.cpdl.org/) as well as audio and video recordings. Finally, music archives contain an increasing number of digitized audio collections of historic value from all around the world such as Flamenco music, Indian art music, Georgian vocal music, or Bejing Opera performances.
Due to its importance, we placed in our seminar a special emphasis on music technologies related to singing. This involves different research areas including singing analysis, description, and modeling (timbre, intonation, expression), singing voice synthesis and transformation, voice isolation/separation, and singing performance rating. Such research areas require a deep understanding of the way people produce and perceive vocal sounds. In our seminar, we discussed such issues with researchers having a background in singing acoustics and music performance.
Over the last years, as is also the case for other multimedia domains, many advances in music and audio processing have benefited from new developments in machine learning.
In particular, deep neural networks (DNNs) have found their way into MIR and are applied with increasing success to various MIR tasks including pitch estimation, melody extraction, sound source separation, and singing voice synthesis. The complex spectro-temporal patterns and relations found in music signals make this domain a challenging testbed for such new machine learning techniques. Music is different from many other types of multimedia. In a static image, for example, objects may occlude one another with the result that only certain parts are visible. In music, however, concurrent musical events may superimpose or blend each other in a more complicated way. Furthermore, as opposed to static images, music depends on time. Music is organized in a hierarchical way ranging from notes, bars, and motifs, to entire sections. As a result, one requires models that capture both short-term and long-term dependencies in music.
In the seminar, we looked at the new research challenges that arise when designing music-oriented DNN architectures. Furthermore, considering the time-consuming and labor-intensive process of collecting human annotations of musical events and attributes (e.g., timbre, intonation, expression) in audio recordings, we addressed the issue of gathering large-scale annotated datasets that are needed for DNN-based approaches.
Participants and Group Composition
In our seminar, we had 32 participants, who came from various locations around the world including North America (4 participants from the U.S.), Asia (4 participants from Japan, 2 from Taiwan, 2 from Singapore, 1 from Korea, 1 from India), and Europe (18 participants from France, Germany, Netherlands, Spain, United Kingdom). More than half of the participants came to Dagstuhl for the first time and expressed enthusiasm about the open and retreat-like atmosphere. Besides its international character, the seminar was also highly interdisciplinary. While most of the participating researchers are working in the field of music information retrieval, we also had participants with a background in musicology, acoustics, machine learning, signal processing, and other fields. By having experts working in technical as well as in non-technical disciplines, our seminar stimulated cross-disciplinary discussions, while highlighting opportunities for new collaborations among our attendees. Most of the participants had a strong musical background, some of them even having a dual career in an engineering discipline and music. This led to numerous social activities including singing and playing music together. In addition to geographical locations and research disciplines, we tried to foster variety in terms of seniority levels and presence of female researchers. In our seminar, 10 of the 32 participants were female, including three key researchers (Anja Volk, Emilia Gómez, and Johanna Devaney) from the "Women in Music Information Retrieval" WiMIR) initiative.
In conclusion, by gathering internationally renowned scientists as well as younger promising researchers from different research areas, our seminar allowed us to gain a better understanding of the problems that arise when dealing with a highly interdisciplinary topic such as melody and voice processing--problems that cannot be addressed by simply using established research in signal processing or machine learning.
Overall Organization and Schedule
Dagstuhl seminars are known for having a high degree of flexibility and interactivity, which allows participants to discuss ideas and to raise questions rather than to present research results. Following this tradition, we fixed the schedule during the seminar asking for spontaneous contributions with future-oriented content, thus avoiding a conference-like atmosphere, where the focus tends to be on past research achievements. After the organizers gave an overview of the Dagstuhl concept and the seminar's overall topic, we started the first day with self-introductions, where all participants introduced themselves and expressed their expectations and wishes for the seminar. We then continued with a small number of short (15 to 20 minutes) stimulus talks, where specific participants were asked to address some critical questions on melody and voice processing in a nontechnical fashion. Each of these talks seamlessly moved towards an open discussion among all participants, where the respective presenters took over the role of a moderator. These discussions were well received and often lasted for more than half an hour. The first day closed with a brainstorming session on central topics covering the participants' interests while shaping the overall schedule and format for the next day. On the subsequent days, we continued having stimulus tasks interleaved with extensive discussions. Furthermore, we split into smaller groups, each group discussing a more specific topic in greater depth. The results and conclusions of these parallel group sessions, which lasted between 60 to 90 minutes, were then presented and discussed with the plenum. This mixture of presentation elements gave all participants the opportunity for presenting their ideas while avoiding a monotonous conference-like presentation format. On the last day, the seminar concluded with a session we called "self-outroductions" where each participant presented his or her personal view on the seminar's results.
Additionally to the regular scientific program, we had several additional activities. First, we had a demo session on Thursday evening, where participants presented user interfaces, available datasets, and audio examples of synthesized singing voices. One particular highlight was the incorporation of singing practice in the seminar. In particular, we carried out a recording session on Wednesday afternoon, where we recorded solo and polyphonic singing performed by Dagstuhl participants. The goal of this recording session was to contribute to existing open datasets in the area of music processing. The singers were recorded with different microphone types such as throat and headset microphones to obtain clean recordings of the individual voices. All participants agreed that the recorded dataset should be made publicly available for research purposes. As preparation for these recordings, we assembled a choir consisting of ten to twelve amateur singers (all Dagstuhl participants) covering different voice sections (soprano, alto, tenor, bass). In the lunch breaks and the evening hours, the group met for regular rehearsals to practice different four-part choral pieces. These musical activities throughout the entire week not only supported the theoretical aspects of the seminar but also had a very positive influence on the group dynamics. Besides the recordings, we also had a concert on Thursday evening, where various participant-based ensembles performed a variety of music including classical music and folk songs.
Conclusions and Acknowledgment
Having a Dagstuhl seminar, we gathered researchers from different fields including information retrieval, signal processing, musicology, and acoustics. This allowed us to approach the problem of melody and voice processing by looking at a broad spectrum of data analysis techniques (including signal processing, machine learning, probabilistic models, user studies), by considering different domains (including text, symbolic, image, audio representations), and by drawing inspiration from the creative perspectives of the agents (composer, performer, listener) involved. As a key result of this seminar, we achieved some substantial progress towards understanding, modeling, representing, and extracting melody- and voice-related information using computational means.
The Dagstuhl seminar gave us the opportunity for having interdisciplinary discussions in an inspiring and retreat-like atmosphere. The generation of novel, technically oriented scientific contributions was not the main focus of the seminar. Naturally, many of the contributions and discussions were on a conceptual level, laying the foundations for future projects and collaborations. Thus, the main impact of the seminar is likely to take place in the medium and long term. Some more immediate results, such as plans to share research data and software, also arose from the discussions. In particular, we plan to make the dataset recorded during the Dagstuhl seminar available to the research community. As further measurable outputs from the seminar, we expect to see several joint papers and applications for funding.
Beside the scientific aspect, the social aspect of our seminar was just as important. We had an interdisciplinary, international, and very interactive group of researchers, consisting of leaders and future leaders in our field. Many of our participants were visiting Dagstuhl for the first time and enthusiastically praised the open and inspiring setting. The group dynamics were excellent with many personal exchanges and common activities. Some scientists expressed their appreciation for having the opportunity for prolonged discussions with researchers from neighboring research fields--something that is often impossible during conference-like events.
In conclusion, our expectations for the seminar were not only met but exceeded, in particular concerning networking and community building. We want to express our gratitude to the Dagstuhl board for giving us the opportunity to organize this seminar, the Dagstuhl office for their exceptional support in the organization process, and the entire Dagstuhl staff for their excellent service during the seminar. In particular, we want to thank Susanne Bach-Bernhard, Annette Beyer, Michael Gerke, and Michael Wagner for their assistance during the preparation and organization of the seminar.
Meinard Müller, Emilia Gómez, and Yi-Hsuan Yang
- Rachel Bittner (Spotify - New York, US) [dblp]
- Estefanía Cano Cerón (A*STAR - Singapore, SG) [dblp]
- Michèle Castellengo (Sorbonne University - Paris, FR) [dblp]
- Pritish Chandna (UPF - Barcelona, ES) [dblp]
- Helena Cuesta (UPF - Barcelona, ES) [dblp]
- Johanna Devaney (Brooklyn College, US) [dblp]
- Simon Dixon (Queen Mary University of London, GB) [dblp]
- Zhiyao Duan (University of Rochester, US) [dblp]
- Emilia Gómez (UPF - Barcelona, ES) [dblp]
- Masataka Goto (AIST - Ibaraki, JP) [dblp]
- Frank Kurth (Fraunhofer FKIE - Wachtberg, DE) [dblp]
- Cynthia Liem (TU Delft, NL) [dblp]
- Antoine Liutkus (University of Montpellier 2, FR) [dblp]
- Meinard Müller (Universität Erlangen-Nürnberg, DE) [dblp]
- Tomoyasu Nakano (AIST - Tsukuba, JP) [dblp]
- Juhan Nam (KAIST - Daejeon, KR) [dblp]
- Ryo Nishikimi (Kyoto University, JP) [dblp]
- Geoffroy Peeters (Telecom ParisTech, FR) [dblp]
- Polina Proutskova (Queen Mary University of London, GB) [dblp]
- Preeti Rao (Indian Institute of Technology Bombay, IN) [dblp]
- Sebastian Rosenzweig (Universität Erlangen-Nürnberg, DE) [dblp]
- Justin Salamon (New York University, US) [dblp]
- Frank Scherbaum (Universität Potsdam - Golm, DE) [dblp]
- Sebastian J. Schlecht (Universität Erlangen-Nürnberg, DE) [dblp]
- Li Su (Academica Sinica - Taipei, TW) [dblp]
- Tomoki Toda (Nagoya University, JP) [dblp]
- Julián Urbano (TU Delft, NL) [dblp]
- Anja Volk (Utrecht University, NL) [dblp]
- Ye Wang (National University of Singapore, SG) [dblp]
- Christof Weiß (Universität Erlangen-Nürnberg, DE) [dblp]
- Yi-Hsuan Yang (Academica Sinica - Taipei, TW) [dblp]
- Frank Zalkow (Universität Erlangen-Nürnberg, DE) [dblp]
Related Seminars
- Dagstuhl Seminar 11041: Multimodal Music Processing (2011-01-23 - 2011-01-28) (Details)
- Dagstuhl Seminar 16092: Computational Music Structure Analysis (2016-02-28 - 2016-03-04) (Details)
- Dagstuhl Seminar 22082: Deep Learning and Knowledge Integration for Music Audio Analysis (2022-02-20 - 2022-02-25) (Details)
Classification
- data bases / information retrieval
- multimedia
- society / human-computer interaction
Keywords
- music information retrieval
- music processing
- singing voice processing
- audio signal processing
- machine learning