Dagstuhl-Seminar 22292
Computational Approaches for Digitized Historical Newspapers
( 17. Jul – 22. Jul, 2022 )



(zum Vergrößern in der Bildmitte klicken)
Permalink
Bitte benutzen Sie folgende Kurz-Url zum Verlinken dieser Seite:
https://www.dagstuhl.de/22292
Organisatoren
- Antoine Doucet (University of La Rochelle, FR)
- Marten Düring (University of Luxembourg, LU)
- Maud Ehrmann (EPFL - Lausanne, CH)
- Clemens Neudecker (Staatsbibliothek zu Berlin, DE)
Kontakt
- Andreas Dolzmann (für wissenschaftliche Fragen)
- Jutka Gasiorowski (für administrative Fragen)
Programm
Context
For long held on library and archive shelving, historical newspapers are undergoing mass digitisation and millions of facsimiles, along with their machine-readable content captured via optical character recognition (OCR), are becoming accessible via a variety of online portals. While this represents a major step forward in terms of preservation and access, it also opens up new opportunities and poses timely challenges for both computer scientists and humanities scholars [2, 1, 3, 14].
As a direct consequence, the last ten years have seen a significant increase of academic research on historical newspaper processing. In addition to decisive grassroots efforts led by libraries to improve OCR technology, individual works dedicated to the development and application of tools to digitised newspaper collections have multiplied [12, 13, 10, 11], as well as events such as evaluation campaigns or hackathons [8, 7, 6, 5]. Besides, several large consortia projects proposing to apply computational methods to historical newspapers at scale have recently emerged, including ViralTexts, Oceanic Exchanges, impresso – Media Monitoring of the Past, NewsEye, Living with Machines, and Data-kbr-be[9].
This momentum can be attributed not only to the long-standing interest of scholars in newspapers coupled with their recent digitisation, but also to the fact that these digital sources concentrate many challenges for computer science, which are all the more difficult – and interesting – since addressing them requires taking digital (humanities) scholarship needs and knowledge into account. Within interdisciplinary frameworks, various and complementary approaches spanning the areas of natural language processing, computer vision, large-scale computing and visualisation, are currently being developed, evaluated and deployed. Overall, these efforts are contributing a pioneering set of tools, system architectures, technical infrastructures and interfaces covering several aspects of historical newspaper processing and exploitation.
Objectives
The aim of the seminar was to bring together researchers and practitioners involved in computational approaches to historical newspapers to share experiences, analyse successes and shortcomings, deepen our understanding of the interplay between computational aspects and digital scholarship, and begin to design a road map for future challenges. Our seminar was guided by the vision of methodologically reflected, competitive and sustainable technical frameworks capable of providing an extensive, sophisticated and possibly dynamic access to the content of digitised historic newspapers in a way that best serves the needs of digital scholarship. We are convinced that in order to meet the many challenges of newspaper processing and to accommodate the demands of humanities scholars, only a global and interdisciplinary approach that looks beyond technical solutionism and embraces the complexity of the source and its study can really move things forward.
Participants and Organisation
The seminar gathered 22 researchers with backgrounds in natural language processing, computer vision, digital history and digital library, the vast majority of whom had previously worked on historical newspapers and were familiar with interdisciplinary environments. To structure and coordinate the work of the seminar, the organisers proposed a mixture of plenary sessions, working groups, and talks, as follows (see also Fig.1):
- Spotlight talks on day 1, where each participant briefly introduced him/herself and gave an opinion or statement on his/her current view of the main topic of the seminar (3-minute/1-slide).
- Demo session, where some participants shortly introduced a relevant asset (e.g., a dataset, tool, interface, on-going experiment).
- Working group sessions, during which groups composed of computer scientists and humanities scholars focused on a specific question. Work within a group featured different moments, with: expert group discussion, where people with similar backgrounds exchanged in order to align their understanding of the question at hand and to prioritise problems; observation of concrete research and workflow practices on existing approaches and/or tools; cross-interviews, where people from one domain interviewed one person from another domain about a specific point; mixed group discussion, where everybody jointly reflected; and writing time, where the group wrote a report summarising its findings.
- Reporting sessions, where working groups reported their discussion and presented their main conclusions and recommendations in a plenary session.
- Morning presentations, where researchers shared their experience from a project and/or their view on a specific topic, followed by a discussion with the participants.
- Evening talks, where researchers shared their experience and views on a topic at large. We proposed three evening lectures that addressed the field of digitised newspapers from the perspective of computer science, digital history, and digital libraries.
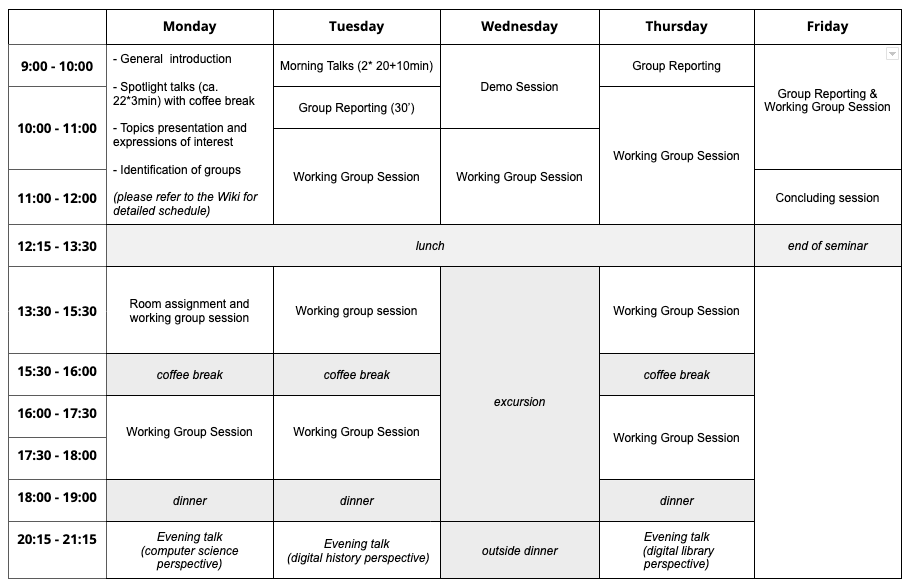
Figure 1 Schedule of the seminar.
Topics
The topics and modus operandi of the seminar were not set in stone but discussed and validated with all participants during the first day. First, the organisers proposed three main topics (and several corresponding sub-questions) for the participants to discuss and reflect on during the seminar. On this basis, participants were then invited to express the specific themes, questions and issues they wished to work on, in a traditional post-it session. Finally, these propositions were examined and structured by the organisers, who defined four working groups.
Proposed topics
As a starting point, organisers proposed to consider three closely intertwined topics, which are detailed below to further illustrate the background knowledge of this seminar.
-
Document Structure and Text Processing. While recent work on the semantic enrichment of historical newspapers has opened new doors for their exploration and data-driven analysis from a methodological perspective (e.g., n-grams, culturomics), results up to now often confirmed common knowledge and were not always considered relevant by historians. The next natural and eagerly-awaited step consists in enriching newspaper contents and structure with semantic annotations which allow for the exploration of far more nuanced research questions. In this regard, several issues arise, among others:
- Q1.1 -- Complex structures and heterogeneity of contents. Newspapers are typically composed of a diverse mix of content including text, image/graphical elements, as well as tabular data and various other visual features. The proper segmentation of the page content into individual information pieces is key for enabling advanced research and analysis. This includes the modelling and detection of logical units on the document (or specifically, issue) level as e.g. articles can span across multiple pages. Also of high relevance to researchers is the more advanced classification and semantic labelling of content units, separating categories such as information, opinion, stock market indices, obituaries, humour, etc. Despite a growing interest, a good understanding of these complex structures as well as methods and technologies for identifying, classifying and accessing diverse content types through appropriate data models and search interfaces are still lacking.
- Q1.2 -- Diachronic processing. Historical newspaper material poses severe challenges for computational analysis due to their heterogeneity and evolution over time. At language level, besides historical spelling variation which leads to major problems in text recognition and retrieval, sequential labelling tasks such as named entity recognition and disambiguation are problematic and often require time-specific resources and solutions. At document level, text classification or topic modelling need to pay attention to the necessary historical contextualisation of their category schemes or corpus time-spans in order to avoid anachronisms. Finally, at structure level, layout processing faces similar challenges and its application needs to adapt to changing sources.
-
Visualisation, Exploitation and Digital Scholarship. Historians and other user groups require tools for content discovery and management to reflect their iterative, exploratory research practices. The opportunities and challenges posed by mass digitised newspapers and other digitised sources require them to adjust their current workflows and to acquire new skills.
- Q2.1 -- Transparency and digital literacy. In the context of research, humanists' trust in computer systems is dependent on sufficient comprehension of the quality of the underlying data and the performance of the tools used to process it. One way to generate such trust is to create transparency, here understood as: information on the provenance and quality of digital sources; information which allows users to make informed decisions about the tools and data they use; and information which allows their peers to retrace their steps. Such transparency empowers users to use the system in a reflective way. But there is to-date no shared understanding of which information exactly is required to achieve transparency: technical confidence scores are themselves hard to interpret and do not translate easily into actionable information. Likewise, historians can not be expected to be aware of the consequences of all the algorithmic treatments to which their digitised sources have been exposed. Instead, the identification of the most relevant biases and their concrete consequences for users appears to be a more realistic approach. Once these are understood, counter-action can be taken.
- Q2.2 -- Iterative content discovery and analysis. In contrast to many other applications in computer science, the discovery of relevant content is of greater interest to historians than the detection of patterns in datasets following a priori hypotheses. Historical research is typically iterative: The study of documents yields new insights which determine future exploration strategies and allow scholars to reassess the value of the sources they have consulted. Semantically enriched content offers multiple ways to support this iterative exploration process. New tools for content discovery also require ``generous'' interfaces, i.e. interfaces which allow users to discover content rather than relying on narrow keyword search [15].
-
System Architecture and Knowledge Representation. The application of various natural language processing and computer vision components which transform noisy and unstructured material into structured data also poses challenges in terms of system architecture and knowledge representation. If those two well-studied fields already offer a strong base to build upon, many questions arise from newspaper source specificities and the digital humanities context.
- Q3.1 -- Managing provenance, complexity, ambivalence and vagueness. Lots of factual and non factual information is extracted from newspaper material and need to be stored and interlinked. In this regard, two points require great attention. First, newspapers -- like any other historical source -- represent past realities which do not necessarily align with present-day realities: institutions and countries change names or merge, country borders move or become disputed and professions change or disappear. These temporal shifts, ambivalences and contradicting information cause historical data to be highly complex and sometimes disputed, and the representation of this complexity poses interesting challenges for computer science. Second, if processing steps, and possibly intermediary representations, of algorithms are recorded for the purpose of transparency, this meta-knowledge need to be stored alongside the data.
- Q3.2 -- Dynamic processing. Historical newspaper processing outputs are useless if not used by scholars who wish to investigate research questions. If all methods and practices can not be transposed as they stand from analogue to digital, careful consideration must be given to how best to accommodate scholarship requirements in digital environments where primary sources are turned into data.
Selected Topics and Working Groups
The discussion around topics led to the definition of four working groups which the participants joined on the first day (on a voluntary basis) and in which they worked throughout the week. No guidelines were given and the groups were free to adapt the direction of their work. Each group wrote a report summarising their activities and findings in Section 4.
- Working Group on Information Extraction. Initiated around the topic of information extraction, this group eventually settled on the specific topic of person entity mentions found in historical newspapers but not present in knowledge bases, a.k.a “hidden people”. The group defined a number of challenges and worked – in a productive hackathon style – on several experiments (see Section 4.1).
- Working Group on Segmentation and Classification. Members of this group quickly discarded the segmentation question to focus on classification only, considering classification scope and practices in relation to digitised newspapers (see Section 4.2).
- Working Group on Transparency, Critics and Newspapers as Data. This group (the largest) worked on a set of recommendations regarding the different aspects of transparency and fairness needed for the analysis of digitised and enriched historical newspaper collections (see Section 4.3).
- Working Group on Infrastructure and Interoperability. This group discussed the issue of consolidation, growth and sustainability of current and future achievements in digitisation, access, processing and exchange of historical newspapers (see Section 4.4).
Spotlight Talks on the Main Challenges Ahead for Digitised Historical Newspapers
On the first morning of the seminar, the organisers asked participants to briefly present their views on some questions they had to consider in advance. These questions were:
- What are the main challenges we need to address in relation with historical newspapers?
- What is the most exciting opportunity you would like to explore during this seminar?
- If you were given €1 million to spend in the next 6 months on historical newspapers, what would you do?
As well as being a good ice-breaker and kick-off to the seminar, the series of responses to these questions documents what a community of researchers in July 2022 believe to be the next challenges for computational approaches to historical newspapers. In total, 21 researchers formulated no less than 67 statements as responses to the first question. In what follows, we provide a summary of the main ideas and suggestions which we have grouped in 8 themes that cover more or less the whole spectrum of activities around digitised newspapers. Apart from this grouping, no further reflection or refactoring has been done on these statements. While most of the answers are not a surprise to those familiar with the subject, they confirm existing needs, reflect on-going trends, and reveal new lines of research.
Document processing. A first group of statements relates to optical character recognition and optical layout recognition (OLR), two critical processes when working with newspapers. These two document image refinement techniques are extremely difficult when applied to such sources (especially for collections digitised long ago), which explains why they are still high on the agenda despite all the efforts invested in recent years. The views expressed highlight and confirm several dimensions, namely: OCR and OLR quality needs to be improved, finer-grained segmentation and classification of news items is necessary, and processes should be more robust across time and collections. Intensive work is being carried out in these areas.
Verbatim statements:
- How to make available digitised newspaper collections in high quality OCR+layout (Clemens Neudecker);
- High quality article segmentation and classification (Maud Ehrmann, Mickaël Coustaty);
- The (massive) segmentation bottleneck (Antoine Doucet);
- Robust layout recognition (Matteo Romanello);
- A level playing field: OCR and fine-grained content segmentation (Marten Düring);
- Improving article segmentation (e.g., wrt advertisements and classifieds) (Mariona Coll-Ardanuy);
- Layout recognition (e.g., article separation, recognition of headings and authors' names) (Dario Kampkaspar);
- OCR+, layout recognition, article segmentation and classification (Eva Pfanzelter);
- Better article segmentation, and a way to deal with heterogeneous qualities of segmentation in DL (Axel Jean-Caurant);
- Quality of OCR across periods, languages and original document qualities (Yves Maurer);
- Standardised approaches to segment historical newspaper pages (Stefan Jänicke).
Text and image processing. This group encompasses all types of content processing applied to OCR and OLR outputs in view of enriching newspaper contents with further information, usually in the form of semantic annotations and item classification. The main challenges that emerge are: robustness (i.e. approaches that perform well on challenging, noisy input), finer-grained information extraction, few-short learning (to compensate lack of training data), transferability (approaches that perform well work across settings), multilinguality, multimodality, entity linking, interlinking of collections, and transmedia approaches.
Verbatim statements:
- Robust multilingual information extraction (Maud Ehrmann);
- Developing methods that are robust to OCR errors (Mariona Coll-Ardanuy);
- Words with meaning change over time (Martin Volk);
- Text summarisation and text classification (monolingual and across languages) (Martin Volk);
- How to automatically detect genres (in particular film reviews and film listings) (Julia Noordegraaf);
- Multilinguality (Eva Pfanzelter);
- Ease multilingual scholarship (qualitative and quantitative) (Antoine Doucet);
- Investigating the relation between (or intertwining of) image and text (Kaspar Beelen);
- Embedding newspaper content within the media landscape (Kaspar Beelen);
- Data mining in newspapers (e.g. biographies, TV/radio programmes) (Marten Düring);
- Robust entity linking (multilingual historical documents) (Matteo Romanello);
- Entity Linking and visualisations over time, space and networks (Martin Volk);
- Linking with other data sources (parliamentary protocols, wiki-data, (historic) names-db, other newspaper portals, (historic) place names db, etc.) (Eva Pfanzelter);
- Create links between newspaper contents (topics, entities) and knowledge bases (Simon Clematide);
- Automate content analysis (discourses, argumentation, events, meaning, topics) to enable historical research (Eva Pfanzelter);
- Learn with few samples and human interactions (Mickaël Coustaty).
Digitisation and Content Mining Evaluation. Here we have grouped together views on the evaluation of technical approaches and tools at large, and the means to implement it. Important points that emerge are: better metrics, more and diverse gold standards, and better contextualisation and understanding of (sources of) errors.
Verbatim statements:
- How to arrive at common methods and metrics for quality of digitised newspapers (Clemens Neudecker);
- Sustainably sharing ground truth datasets and training models (Sally Chambers);
- Developing a variety of NLP benchmarks for different tasks across different languages and types of publications (Mariona Coll-Ardanuy);
- Build a general taxonomy of content items (including ads, service tables, etc.) and prepare well-sampled data sets from a variety of publication places and time periods (Simon Clematide);
- Disentangling correlation of errors and missingness with time, place, language, network position, etc. (David Smith).
Exploration of (enriched) newspaper collections and beyond. One of the opportunities that researchers have been working on in recent years is new ways of exploring newspaper content. This group of statements is part of this context and highlights some of the longawaited next steps: unified access to newspaper collections, support for data-driven research, and connection to other archives.
Verbatim statements:
- Access to newspaper content across collections/projects/platforms (Matteo Romanello);
- Unified access to all collections with advanced exploration capacities (Maud Ehrmann);
- A unified framework to REALLY make collections accessible, usable and interoperable (Antoine Doucet);
- Access across collections and copyright hurdles (Marten Düring);
- Silos (Jana Keck);
- Data-driven linking and analysis of multiple types of sources (e.g. radio, TV, parliamentary records) and datasets (e.g. land ownership, migration) (Marten Düring);
- User-driven (from novice to expert) image, information and metadata etc. extraction (Eva Pfanzelter);
- Offer our users more than search, but what ? Topics, recommenders, \ldots ? (Yves Maurer);
- Contextual information extracted from the corpus: hints on rubrics, themes, top keyword per month etc. (Estelle Bunout);
- Comparative analyses of contents (political targets of publishers), ordering of articles and time-based development of topics (Stefan Jänicke).
Working with data. In addition to working with enriched sources that can be semantically indexed and thus more easily retrieved and analysed, researchers (especially historians) also express the wish to work directly with raw data – digitised documents, annotations, or both – and be able to build their own corpora.
Verbatim statements:
- How to create useful datasets and corpora from digitised newspapers (Clemens Neudecker);
- Availability of digitisation output (images, text) for further use (beyond interfaces) (Estelle Bunout);
- Newspapers as Data: how to facilitate dataset / corpus building (Sally Chambers);
- Ease the building and sharing of corpora, taking into account the context of creation (queries, quality, etc) (Axel Jean-Caurant).
Collections, source and tool criticism; Documentation; Inclusivity. The validity of any conclusions drawn in empirical research depends on a solid understanding of the data used for the analysis. Digitised and enriched newspapers contain multiple levels of processing which often vary significantly across titles in terms of processing quality and extent of enrichment. The statements below point to key challenges and opportunities to advance our reflected analysis of digitised newspapers.
Verbatim statements:
- How to support and perform source criticism on digitised newspaper collections (Julia Noordegraaf);
- Methodological guidelines for the computational analysis of newspaper content (Julia Noordegraaf);
- Describing how biases arise in digitised newspapers collections (``full-stack bias'') (Kaspar Beelen);
- Understanding how structured missingness and data quality affect (historical) research (Kaspar Beelen);
- Selection criteria guidelines for what is being selected, digitised, accessible and how it is represented, searchable, and available (Jana Keck);
- Trustable and/or understandable approaches to meet users' needs (Mickaël Coustaty);
- How do we make collections as well as access mechanisms inclusive? (Laura Hollink);
- How do we monitor fairness of computational approaches to historic newspapers? (Laura Hollink);
- How well does the collection support different user groups? (Laura Hollink);
- How do we make perspectives in the data explicit? (e.g in NL context: words signalling a colonial perspective) (Laura Hollink);
- Information on the scope, contents and quality of a collection, e.g., included titles, covered time periods, granularity of items (page vs. article), OCR quality, corpus statistics (Estelle Bunout);
- Investigate the role of attributes like font face and style, margins, layout, paper, etc. (Stefan Jänicke);
- Book-historical studies of editorship and publishing (costs, layout, format, advertising, syndicates, networks) crossing national and cataloguing (newspaper/magazine) boundaries (David Smith) ;
- Investigate the role of attributes like font face and style, margins, layout, paper, etc. (Stefan Jänicke).
Workflows. The combination of multiple processes, moreover between different actors, requires the design of more standardised and efficient workflows encompassing the many processing steps that have emerged in recent years.
Verbatim statements:
- Advanced digitisation workflows: from digitisation to OCR to article segmentation (Sally Chambers);
- Workflows that conflate search, annotation, classification, corpus construction (David Smith).
Legal matters. Finally, a last set of (unavoidable) challenges concerns legal issues, with questions of copyright clearance and management, and of personal data, whether it be user data handled by platforms, or the right to be forgotten.
Verbatim statements:
- Find sustainable ways to work with copyright-restricted data sets (Yves Maurer);
- Access across collections and copyright hurdles (Marten Düring);
- Copyrights and proprietary rights, image rights etc. (Eva Pfanzelter);
- Legal questions (copyright, personal rights, etc.) (Dario Kampkaspar).
Acknowledgements
This seminar was originally planned for September 2020 but was cancelled due to the COVID-19 pandemic and rescheduled 2 years later. We would like to thank the administrative and scientific teams at Dagstuhl for their support and professionalism throughout the (re)organisation of this seminar as well as the staff on site for their valuable every day help and care. We also thank all the participants for accepting our invitation to spend a week exchanging views, examining, questioning, debating (and writing) about computational approaches to historical newspapers.
References
- Bingham, A. The Digitization of Newspaper Archives: Opportunities and Challenges for Historians. Twentieth Century British History.21, 225-231 (2010,6)
- Deacon, D. Yesterday’s Papers and Today’s Technology: Digital Newspaper Archives and “Push Button” Content Analysis. European Journal Of Communication. 22, 5-25 (2007)
- Nicholson, B. The Digital Turn. Media History. 19, 59-73 (2013,2)
- Neudecker, C., Baierer, K., Federbusch, M., Boenig, M., Würzner, K., Hartmann, V. & Herrmann, E. OCR-D: An End-to-End Open Source OCR Framework for Historical Printed Documents. Proceedings Of The 3rd International Conference On Digital Access To Textual Cultural Heritage. pp. 53-58 (2019,5)
- Ehrmann, M., Romanello, M., Najem-Meyer, S., Doucet, A. & Clematide, S. Extended Overview of HIPE-2022: Named Entity Recognition and Linking in Multilingual Historical Documents. Proceedings Of The Working Notes Of CLEF 2022 – Conference And Labs Of The Evaluation Forum. 3180 (2022) https://infoscience.epfl.ch/record/295816
- Ehrmann, M., Romanello, M., Flückiger, A. & Clematide, S. Extended Overview of CLEF HIPE 2020: Named Entity Processing on Historical Newspapers. Working Notes Of CLEF 2020 – Conference And Labs Of The Evaluation Forum. 2696 pp. 38 (2020)
- Clausner, C., Antonacopoulos, A., Pletschacher, S., Wilms, L. & Claeyssens, S. PRImA, DMAS2019, Competition on Digitised Magazine Article Segmentation (ICDAR 2019). (2019), https://www.primaresearch.org/DMAS2019/
- Rigaud, C., Doucet, A., Coustaty, M. & Moreux, J. ICDAR 2019 Competition on Post-OCR Text Correction. 2019 International Conference On Document Analysis And Recognition (ICDAR). pp. 1588-1593 (2019)
- Ridge, M., Colavizza, G., Brake, L., Ehrmann, M., Moreux, J. & Prescott, A. The Past, Present and Future of Digital Scholarship with Newspaper Collections. DH 2019 Book Of Abstracts. pp. 1-9 (2019), http://infoscience.epfl.ch/record/271329
- Kestemont, M., Karsdorp, F. & Düring, M. Mining the Twentieth Century’s History from the Time Magazine Corpus. Proceedings Of The 8th Workshop On Language Technology For Cultural Heritage, Social Sciences, And Humanities (LaTeCH). pp. 62-70 (2014)
- Lansdall-Welfare, T., Sudhahar, S., Thompson, J., Lewis, J., Team, F. & Cristianini, N. Content Analysis of 150 Years of British Periodicals. Proceedings Of The National Academy Of Sciences. 114, E457-E465 (2017)
- Moreux, J. Innovative Approaches of Historical Newspapers: Data Mining, Data Visualization, Semantic Enrichment. IFLA News Media Section, Lexington, August 2016, At Lexington, USA. (2016,8), https://hal-bnf.archives-ouvertes.fr/hal-01389455
- Wevers, M. Using Word Embeddings to Examine Gender Bias in Dutch Newspapers, 1950- 1990. Proc. Of The 1st International Workshop On Computational Approaches To Historical Language Change. (2019), https://www.aclweb.org/anthology/W19-4712
- Bunout, E., Ehrmann, M. & Clavert, F. (editors) Digitised Newspapers – A New Eldorado for Historians? Tools, Methodology, Epistemology, and the Changing Practices of Writing History in the Context of Historical Newspaper Mass Digitisation. De Gruyter (2022, in press), doi:10.1515/9783110729214, https://www.degruyter.com/document/ isbn/9783110729214/html
- Whitelaw, M. Generous Interfaces for Digital Cultural Collections. Digital Humanities Quarterly. 9 (2015), http://www.digitalhumanities.org/dhq/vol/9/1/000205/000205. html
- Ehrmann, M., Bunout, E. & Düring, M. Historical Newspaper User Interfaces: A Review. Proceedings Of The 85th International Federation Of Library Associations And Institutions (IFLA) General Conference And Assembly. pp. 24 (2019), https://infoscience.epfl.ch/ record/270246?ln=en
 Creative Commons BY 4.0
Creative Commons BY 4.0
 Maud Ehrmann, Marten Düring, Clemens Neudecker, and Antoine Doucet
Maud Ehrmann, Marten Düring, Clemens Neudecker, and Antoine Doucet
Historical newspapers are mirrors of past societies. Published over centuries on a regular basis, they keep track of the great and small history and reflect the political, moral and economic environments in which they were produced. They also hold dense, continuous, and multimodal information which, coupled with their inherent contextualization, makes them invaluable primary sources for the humanities. They are in high demand by scholars and the general public, have been digitized in huge numbers and pose timely challenges for computer scientists and humanities scholars.
Following the decisive efforts led by libraries around the world to improve optical character recognition (OCR) technology and generalize full text digitization and access, recent years have seen a notable increase of academic research initiatives around historical newspaper processing. This momentum can be attributed not only to the long-term interest of humanities scholars in newspapers coupled with their recent digitization, but also to the fact that these digital sources concentrate many challenges for computer science, especially computational linguistics and computer vision, all the more difficult—and interesting—since tackling them requires to take digital (humanities) scholarship needs and knowledge into account. Within interdisciplinary frameworks, various and complementary approaches spanning the areas of natural language processing, computer vision, large-scale computing and visualization, are currently being developed, evaluated and deployed. Overall, these efforts are contributing a pioneering set of tools, system architectures, technical infrastructures and interfaces covering several aspects of historical newspaper processing and exploitation. In this context, the Dagstuhl Seminar aims to gather researchers and practitioners involved in this endeavour in order to share experiences, analyze successes and shortcomings, deepen our understanding of the interplay between computational aspects and digital scholarship, and design a roadmap for future challenges.
Three closely intertwined challenges stand out and will be considered: First, historical newspapers pose great challenges in terms of document and text processing. Recognition of the complex and varying layout and structure is still out of reach of current algorithms, and noisy OCR, language change and lack of domain-specific resources undermine traditional information extraction approaches. Second, system architecture and knowledge representation describe the increased need for standardized and modular information flows between systems. Open questions include the scalable integration of various processing components, and the accommodation of scholar research requirements. Third, historians and other user groups require tools for content discovery and management to reflect their iterative, exploratory research workflows. Here, the potential of personalized recommendation systems and visualizations still awaits full exploitation. To generate trust in systems, users also require more transparency regarding algorithmic outputs and the exploitation of inherently imperfect, uncertain data.
Solutions to these challenges require the close collaboration of experts in computer science, digital history and library and information science. The seminar will be organized around a set of abstracted problems derived from the above-mentioned challenges and propose strategies to resolve them.
Antoine Doucet, Marten Düring, Maud Ehrmann, and Clemens Neudecker
Vor Ort
- Kaspar Beelen (The Alan Turing Institute - London, GB)
- Estelle Bunout (University of Luxembourg, LU) [dblp]
- Sally Chambers (Ghent University, BE & KBR, Royal Library of Belgium, Brussels, BE) [dblp]
- Simon Clematide (Universität Zürich, CH)
- Mariona Coll-Ardanuy (The Alan Turing Institute - London, GB)
- Mickaël Coustatsy (University of La Rochelle, FR) [dblp]
- Marten Düring (University of Luxembourg, LU) [dblp]
- Maud Ehrmann (EPFL - Lausanne, CH) [dblp]
- Laura Hollink (CWI - Amsterdam, NL) [dblp]
- Stefan Jänicke (University of Southern Denmark - Odense, DK) [dblp]
- Axel Jean-Caurant (University of La Rochelle, FR) [dblp]
- Dario Kampkaspar (TU Darmstadt, DE) [dblp]
- Jana Keck (German Historical Institute Washington, US)
- Yves Maurer (National Library of Luxembourg, LU)
- Clemens Neudecker (Staatsbibliothek zu Berlin, DE) [dblp]
- Julia Noordegraaf (University of Amsterdam, NL) [dblp]
- Eva Pfanzelter (Universität Innsbruck, AT)
- David A. Smith (Northeastern University - Boston, US) [dblp]
- Martin Volk (Universität Zürich, CH) [dblp]
- Lars Wieneke (C2DH - Esch-sur-Alzette, LU) [dblp]
Klassifikation
- Computation and Language
- Computer Vision and Pattern Recognition
- Information Retrieval
Schlagworte
- natural language processing
- document structure and layout analysis
- information extraction
- digital history
- digital scholarship